Failures are unexpected, but they are also a great learning opportunity, and I've decided to do just that.
I was asked a super simple question, that unexpectedly had me try to solve it in a totally wrong context, and that made me loose sight of the question in the first place.
My first mistake...
My brain immediately switched into "hmm, what's the best way to solve this in Rust at 10,000ft...", and the first thing I wrote was something along the lines of "
pub struct SellerItems<Vec<(HashMap<_>)>>" or something like that. It was bloody awful and my brain shutdown. Taking me outside my comfort zone, was the requirement of writing "pseudocode" in a Google doc. No NeoVim, Rust-analyzer, nada... niet!Instead, I should have taken a piece of paper and started modelling data in memory in terms of
ptrs and heap, in a C++ context.Challenge question.
Unlike eBay, assume a user sees a UI and can type in descriptive text, and then can enter an amount that they wish to sell the item for. The buyer can also provide text input and the max they are willing to pay. If there is a direct match on the text phrase, provide a yes/no answer to the buyer. It has to happen instantly in memory; ignore all I/O, databases etc etc. You need to write two functions to add items and search through them. Assume the provided text is pre-sanitised as alphanumeric strings containing spaces only.
Bear with me as the above roughly paraphrases what was said.
Second mistake...
My first fumble, just started to recurse and what threw me the most was I needed to write "pseudo code" in a text editor, over a live screen share. This was the wild wild west, no longer did I have the glow of Zellij, neo-vim, or VSCode.
Solving in Rust
The above question should have been addressed in the context of Data structures, pointers, allocations on the
stack and heap. Elements (for sale) are added with an add_many() function and a search() function processes the elements in memory, following any ptrs back to the text Strings on the heap.One key take away from this failed approach is that it is better to design (even in Rust) with primitive structures first, before scaling up to record structs, and/or tuple-structs. This is because, especially with tuple structs, one has to account for its inner args, such as
self.0, self.1 etc. or using tuple destructuring.It's far easier to resolve such issues iterating with Rust-Analyzer (RA) and Rust's compiler error report - but not so with a plain text editor.
I do however prefer to leverage my strengths and this article will take you through that process.
Writing this in Rust
Let's look at a viable means for adding and holding the text values in a RAM,
pub struct Entries(pub HashMap<String, f64>);
impl Entries {
pub fn new() -> Self {
Self(HashMap::new())
}
pub fn len(&self) -> usize {
self.0.len()
}
pub fn add_many<'a>(&mut self, items: impl IntoIterator<Item = (&'a str, f64)>) {
let new: HashMap<String, f64> =
items.into_iter().map(|(k, v)| (k.to_string(), v)).collect();
self.0 = new;
}
// ...
}Recall how I said that my first mistake let to an avalanche of confusing myself, well, it turns out that wasn't where I lost the plot after all. I'm using something rather similar here with
struct Entries(pub HashMap<String, f64>) and have a couple instance methods (those that take &self and &mut self) and of course new() to allow easy instantiation of an instance.Notice that
add_many() takes a items: impl IntoIterator<Item = (&'a str, f64)>) as a parameter, which needs life time annotation for the &str, but most importantly I'm using an Impl IntoIterator<Item = ()> here.You can find a working solution here, although I'm pushing some final improvements to the docs around it in
/benchmarking.Optimising with Flamegraph
Running
./src/string_search/run-flamegraph.sh with an earlier inefficiency in Entries::search() (SHA: 9056922) revealed 
This naive approach had an unnecessary allocation by collecting into a Vector
let haystack: Vec<String> = self.0.iter().map(|el| el.0.to_string()).collect(); - However, HashMap has contains_key() and get() which returns an Option<_>
Once switching to using the latter on the primitive
HashMap we can see our Flamegraph improve considerably, even with 1 Million invocations of our search() function
Running Heaptrack in Debian
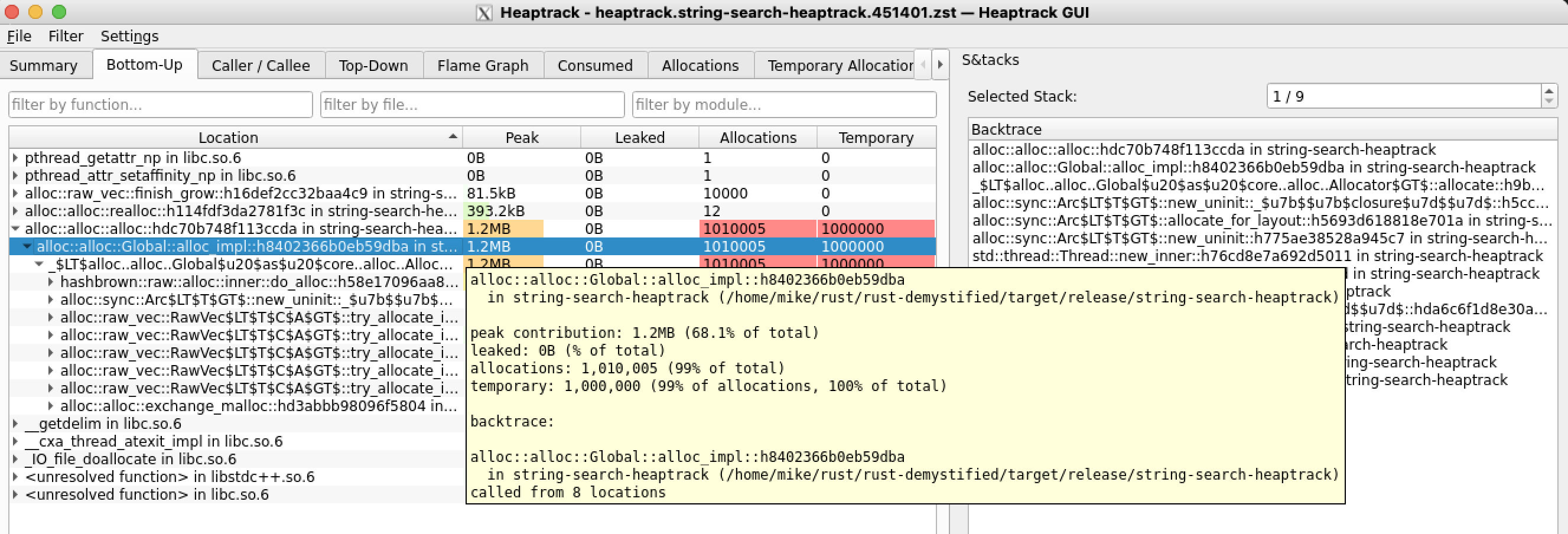
I noticed we had a Million allocations, for a return value in search() but this is because the return type is rather silly. We are searching for a needle and we know that we get a non Error if there is a match, so why bother returning the same data, but heap allocated?
This is fixed in SHA
df0702c
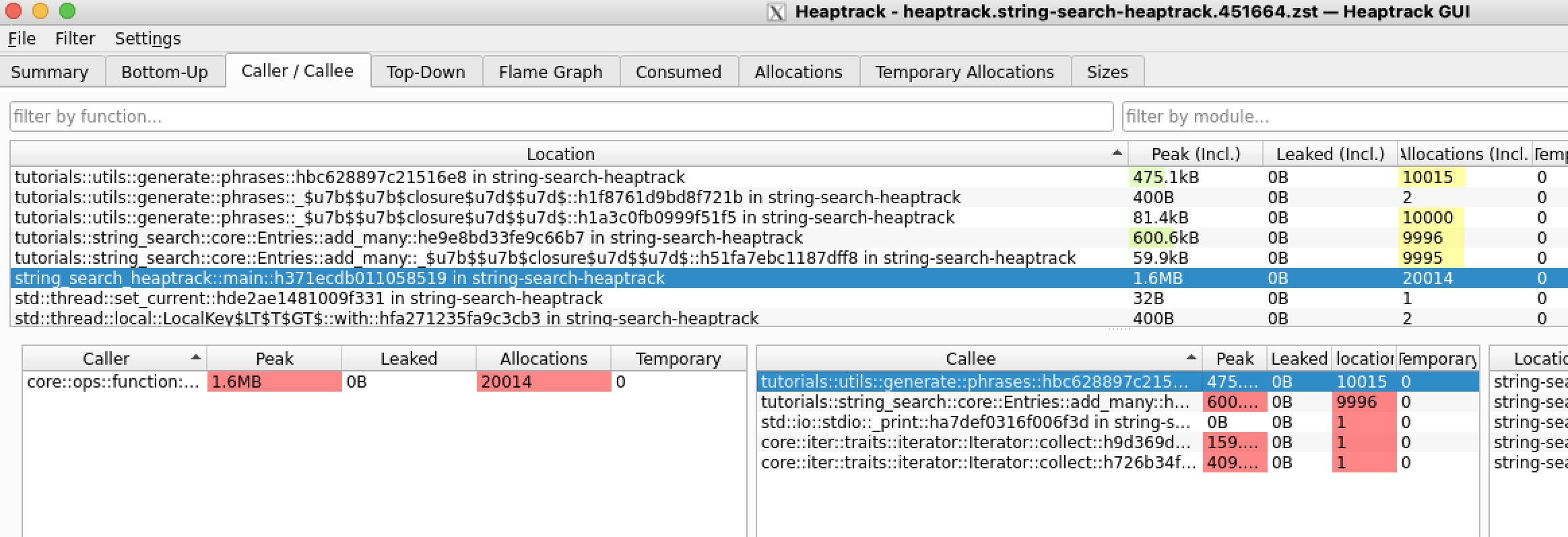
These allocations are quite clearly shown and are tied to our
phrases() and add_many() functions.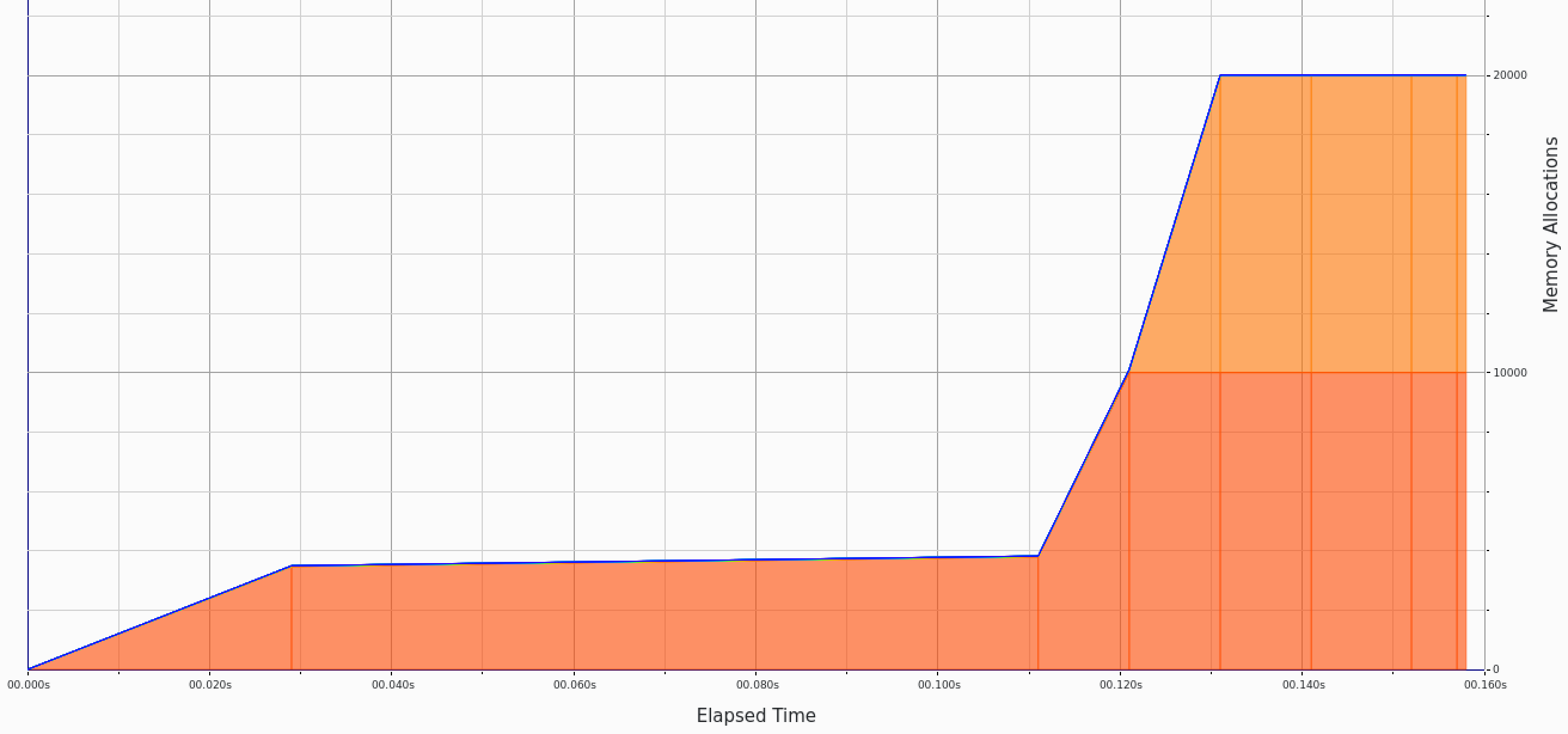
Searching for
HashMap operations we can see the very limited allocs in the centre column. Since phrases and add_many() are on either side, we can conclude this is where search is taking place
References
Acknowledgements & Thanks
- Helix (noop_noob) (aka. helix65535) for all your help and guidance.